
.png)
Table of Contents
This is the vCluster performance paradox, and it’s a question that deserves a clear, no-nonsense answer. As a technology designed to solve Kubernetes multi-tenancy, bare metal CPU and GPU sharing and ephemeral environments to Kubernetes with a lighter footprint, vCluster promises significant economic advantages. In this blog post, we'll demystify how vCluster achieves these savings and, crucially, how it’s engineered to deliver robust performance even in high-density environments.
The "Millions Saved" - Unpacking vCluster's Economic Advantages
Let’s try to understand how vCluster can save Enterprises a very large amount of development and operations costs. This isn’t just a marketing number but a direct result of fundamental architectural shifts that vCluster enables.
1. 50 separate clusters vs 50 virtual clusters using vCluster
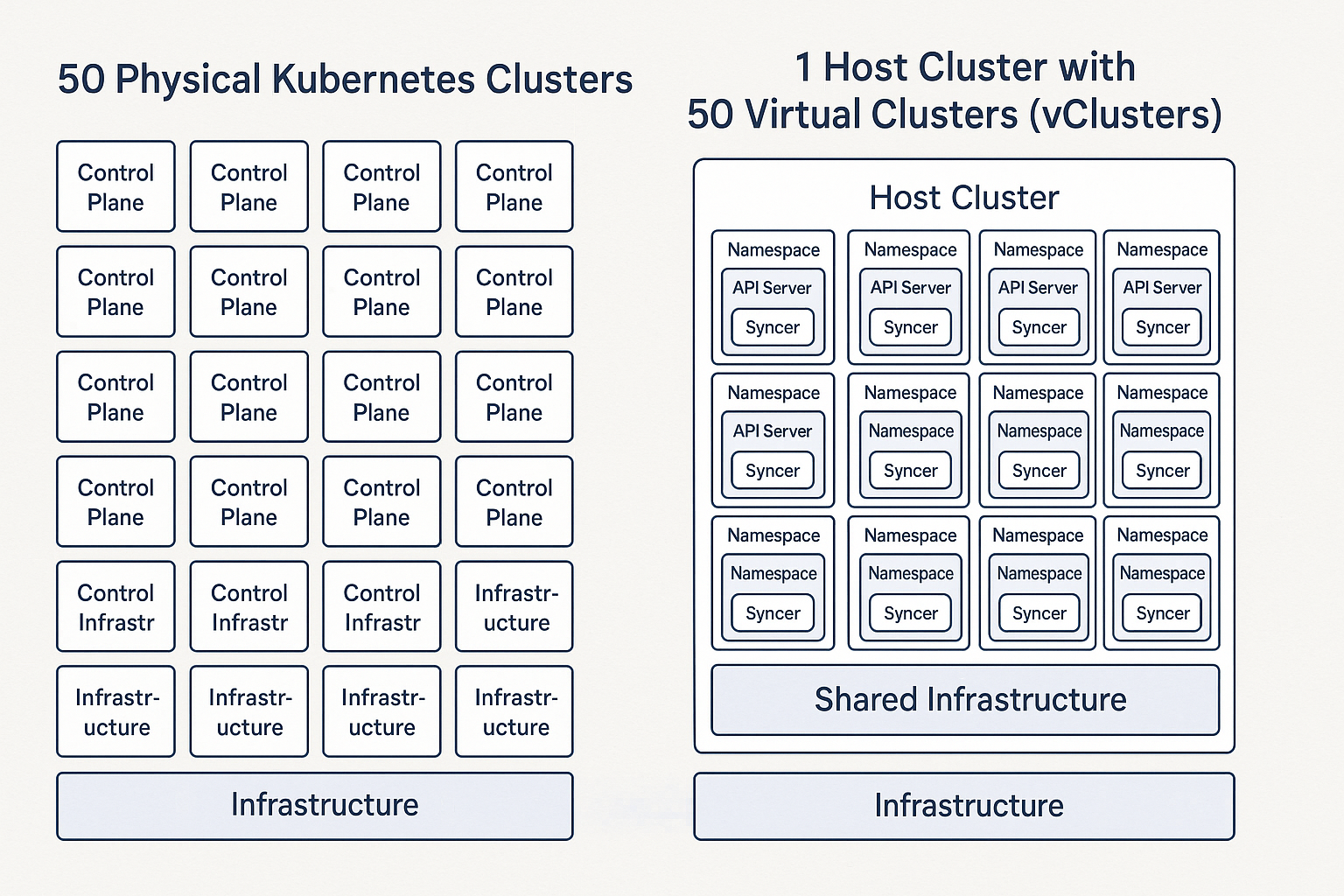
Imagine managing 50 separate Kubernetes clusters. In a traditional setup, this means you're operating 50 distinct control planes on AWS, GCP, or bare metal. Each control plane (comprising the API server, etcd, scheduler, and controllers) demands dedicated compute resources – often multiple virtual machines or even bare metal servers, replicated for high availability. This quickly escalates into substantial infrastructure costs, especially with cloud-managed Kubernetes services like Amazon EKS, Google GKE, or Azure AKS, where the control plane itself carries an hourly fee. Moreover, if you fall behind with your Kubernetes upgrades, this fee can skyrocket.
With vCluster, this paradigm flips. You manage just one powerful host Kubernetes cluster. The 50 virtual clusters you create within it run incredibly lightweight control planes which are CNCF certified. These vCluster control planes exist as simple pods, consuming minimal resources directly on the host cluster's worker nodes. This drastic reduction in dedicated control plane infrastructure is the single largest contributor to cost savings.
2. Unlocking Node Utilization & Resource Bin-Packing
Traditional, isolated clusters often lead to significant resource waste. Teams or environments (dev, test, staging) tend to provision clusters to meet peak demand, inevitably leaving nodes idle or underutilized for much of the time. Even with powerful autoscaling tools like Kubernetes Cluster Autoscaler or Karpenter (which, despite its advantages, doesn't yet have seamless integration with all cloud providers), achieving genuinely optimal utilization remains a challenge. These tools help, but the fundamental isolation of separate clusters still means you're often paying for unused capacity.
vCluster tackles this head-on. By consolidating all workloads onto a single, larger host cluster, you achieve superior "bin packing" of pods. Resources on the host cluster's nodes are dynamically shared across all 50 vClusters.A killer feature here is vCluster's "sleep mode." For ephemeral or development environments, vCluster can automatically scale down all pods within an inactive virtual cluster to zero, effectively pausing resource consumption until it's accessed again. This intelligent management of idle resources dramatically reduces your cloud spend.
3. Shared Platform Stack
Traditionally when you provision a Kubernetes cluster you are required to install cert-manger, Istio, ingress controller, Kubeflow and with 50 Kubernetes clusters, you repeat the process 50 times across those 50 clusters each consuming resources. But in the vCluster scenario, you install these once on the host cluster, and share across all 50 virtual clusters providing a significant resource benefit..
For example you do not need a separate Ingress controller running in each of your 50 vClusters. Instead, a single, shared Ingress controller (e.g., NGINX Ingress, Traefik) deployed on the host cluster can serve traffic for all vClusters. The vCluster Syncer takes care of synchronizing the Ingress resources from the virtual cluster to the host, ensuring the host's Ingress controller routes traffic correctly. This drastically reduces resource consumption and simplifies network management.
4. Operational Efficiency & Staff Time Savings
Beyond infrastructure, the operational overhead of managing 50 independent Kubernetes clusters is immense. Each requires its own set of upgrades, patching, security configurations, monitoring, and troubleshooting. This consumes valuable time from highly paid DevOps and SRE teams.
vCluster streamlines operations:
- Centralized Management: Many tasks are centralized to the host cluster.
- Faster Provisioning: Spinning up a new vCluster takes seconds, compared to minutes or tens of minutes for a full-fledged cluster, accelerating CI/CD pipelines and developer onboarding.
- Simplified RBAC: Developers can be granted administrative privileges within their isolated vCluster without needing host-level access, enhancing security and reducing complexity.
By reducing management complexity and workload, thus freeing up engineering talent, vCluster allows your teams to focus on innovation rather than infrastructure maintenance.
Let’s talk about the Performance - Addressing Your Concerns
While it is called a virtual cluster, there is no virtualization in a traditional sense, no virtual machines or hypervisors to introduce overhead for the applications you will deploy.
Now for the critical question: how does vCluster achieve these efficiencies without bogging down performance? The answer lies in its clever architecture and strategic use of Kubernetes' capabilities.
1. Understand vCluster Architecture: The Syncer is Key!
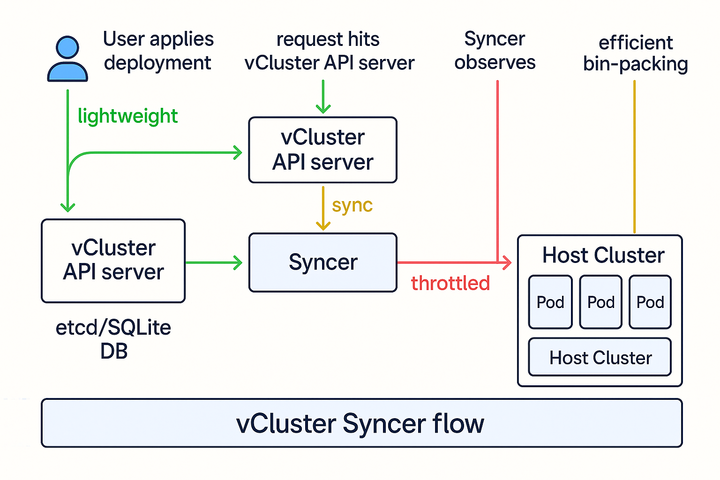
This is where understanding the magic is critical. When a user or an application within a vCluster makes an API request (e.g., kubectl get pods, kubectl create deployment), this request first goes to the vCluster's own lightweight API server. The vCluster's API server processes these high-level requests and stores them in its own internal etcd (or SQLite database).
The real innovation is Syncer. This process is responsible for reconciling the state of resources inside the vCluster with the state of resources on the host cluster.
For example:
- You create a Deployment in your vCluster.
- The vCluster's API server records this.
- The Syncer observes this Deployment and then makes the necessary API calls to the host cluster's API server to create the actual low-level resources like ReplicaSets, Pods, Volumes, and Services in a dedicated namespace on the host.
So, while direct user interaction is with the vCluster's API, the Syncer does generate traffic to the host cluster's API server. This is the crucial point for performance considerations.
2. API Server Performance (Host & Virtual)
- vCluster API Server Performance: Each vCluster has its own dedicated API server. Because these are lightweight and isolated, the performance for operations within a single vCluster tends to be excellent. The vCluster's control plane is designed for efficiency, often using intelligently packed Kubernetes to minimize overhead.
- Host Cluster API Server Performance: The Potential Bottleneck & Its Protections: This is the point where concerns about "overwhelming" the host arise. If 50 vClusters simultaneously unleash a flood of changes, the cumulative load on the host cluster's API server could indeed become an issue. However, vCluster is specifically designed to mitigate this:
- Intelligent Syncer: The syncer doesn't just blindly forward every request. It intelligently translates and aggregates changes, only sending the necessary low-level resource updates to the host API. For instance, creating a Deployment in the vCluster results in fewer, more targeted calls to the host API for the underlying pods.
- Crucial Role of Rate Limiting: While the --max-requests-inflight and --max-mutating-requests-inflight flags are essential for the Kubernetes API server itself (both the vCluster's and the host's), in the vCluster context, the more direct control for protecting the host API server comes from the rate limits configured on the vCluster's internal API client that the syncer uses to communicate with the host. This client-side rate limiting (often configured via QPS and Burst settings, and potentially exposed through environment variables like VCLUSTER_PHYSICAL_CLIENT_QPS and VCLUSTER_PHYSICAL_CLIENT_BURST as seen in recent development efforts) directly throttles the number of requests the syncer can make to the host. This ensures that even if a vCluster is highly active internally, its demands on the host are controlled. By default vCluster comes with reasonable defaults already.
- API Priority and Fairness (APF): For Kubernetes versions 1.20 and newer on the host cluster, APF further enhances resilience. Even if a burst of requests hits the host API server, APF ensures that critical requests are prioritized, maintaining the stability of the entire system.
3. Networking Performance
You might wonder about network impact with multiple virtual clusters. Here's how it shakes out:
- Intra-vCluster (Pods & Services): Pods within the same vCluster communicate with native performance. This is because, ultimately, vCluster pods are scheduled and run directly on the host cluster's nodes, leveraging the host's underlying CNI (Container Network Interface). There's no network overhead introduced by the “virtualization” layer itself for inter-pod communication.
- Cross-vCluster / vCluster-to-Host Communication: If applications in different vClusters (or a vCluster and the host cluster) need to communicate, this is achievable. Unlike separate host clusters where cross-cluster traffic typically routes via external Gateways or Ingress controllers, vClusters can leverage the direct network of the shared host cluster. This allows for more direct communication between application containers, positively impacting speed and reducing latency. While specific network policies or service mesh configurations might still be involved for security or advanced routing, the underlying shared network streamlines the communication path.
Strategic Implementation for Optimal Results
vCluster comes with reasonable defaults but you can improve vCluster's benefits by:
- Size Your Host Cluster Wisely: Ensure your host Kubernetes cluster has sufficient CPU, memory, and network capacity to handle the aggregate workload of all your vClusters — including Syncer activity.
- While it's important to plan for peak usage, note that because vClusters often share resources efficiently, you can size your host below the theoretical maximum of all clusters combined due to non-overlapping usage patterns.
- Recommendation:
- Instead of static sizing, enable auto-scaling (Cluster Autoscaler / Karpenter / cloud-native equivalents) for your host cluster to dynamically adapt to the workload of the vClusters. This reduces waste during idle times and ensures availability during spikes.
- Leverage Complementary Kubernetes Features:
- Resource Quotas: Apply resource quotas on the namespaces provisioned for vClusters on the host cluster to cap their overall resource consumption.
- Pod Limits: Continue to apply CPU and memory limits on individual pods within your vClusters.
- Network Policies: Utilize network policies on the host to control communication between vClusters for security and isolation.
- Robust Monitoring & Observability: Implement comprehensive monitoring for both your host cluster (especially its API server) and the vCluster components (API server pods, Syncer pods). This visibility is crucial for identifying bottlenecks, fine-tuning configurations, and proactively addressing performance issues.
Conclusion
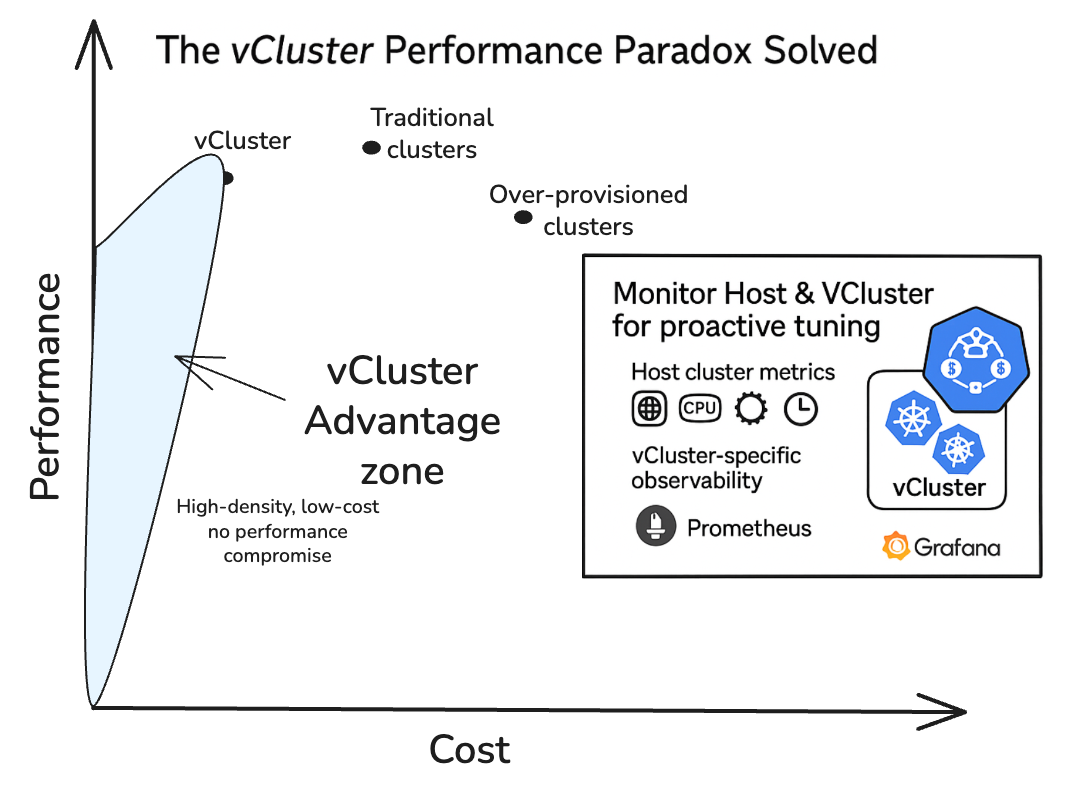
The claim of vCluster enabling huge cost savings is not an exaggeration; it's a testament to its efficiency in reducing control plane overhead, maximizing resource utilization, and streamlining operations. There is often a "performance paradox" in multi-tenant Kubernetes environments where achieving cost savings is assumed to come at the expense of performance. vCluster resolves this paradox through its intelligent architecture, particularly the role of the Syncer and the vital application of API server rate limiting.
vCluster isn't about sacrificing performance for cost. Instead, it's about optimizing how Kubernetes resources are consumed and managed, enabling multi-tenancy and ephemeral environments that are both highly cost-efficient and performant. For organizations looking to scale their Kubernetes footprint without spiraling costs, vCluster offers a compelling and practical solution.
So, the next time you hear about vCluster and its economic benefits, you can confidently explain that its performance capabilities are not an afterthought, but an integral part of its design.
.png)
.png)
.png)