
.png)
Table of Contents
Kubernetes adoption is increasing, with organizations relying on it as the foundation for deploying and scaling their applications. Internally, more teams are migrating their infrastructure to Kubernetes, attracted by its flexibility and the promise of more efficient operations. To handle this growing complexity, platform engineering has become a key discipline, providing a way to optimize Kubernetes use through self-service tooling, automation, and internal developer platforms.
As adoption grows, organizations start to experiment with different cluster strategies: shared clusters, dedicated clusters for each team, and even local development clusters. Each approach tries to balance efficiency with team independence. However, shared Kubernetes clusters, while cost-effective, often become a bottleneck as diverse teams compete for resources and operational control.
This post will compare the commonly used shared cluster strategy and explore the challenges and benefits of adopting a new virtual cluster strategy to maximize productivity and reduce costs during platform development.
Kubernetes Controllers: The Fundamental Block
As more developers build and use platforms internally within organizations, platform teams turn to controllers to enhance Kubernetes' capabilities. These controllers help create reusable abstractions, manage infrastructure as code, and enforce governance.
Most controllers can be categorized into third-party (open source and commercial) and in-house, which are built by the team based on their specific use case. With their individual life cycles, these controllers encompass a lot of business and infrastructure logic.
Since these controllers are part of your cluster and multiple controllers from different or similar providers, possibly with various versions during production, development, and rollout, there can be conflicts and architectural requirements that need to be addressed to accommodate the controllers.
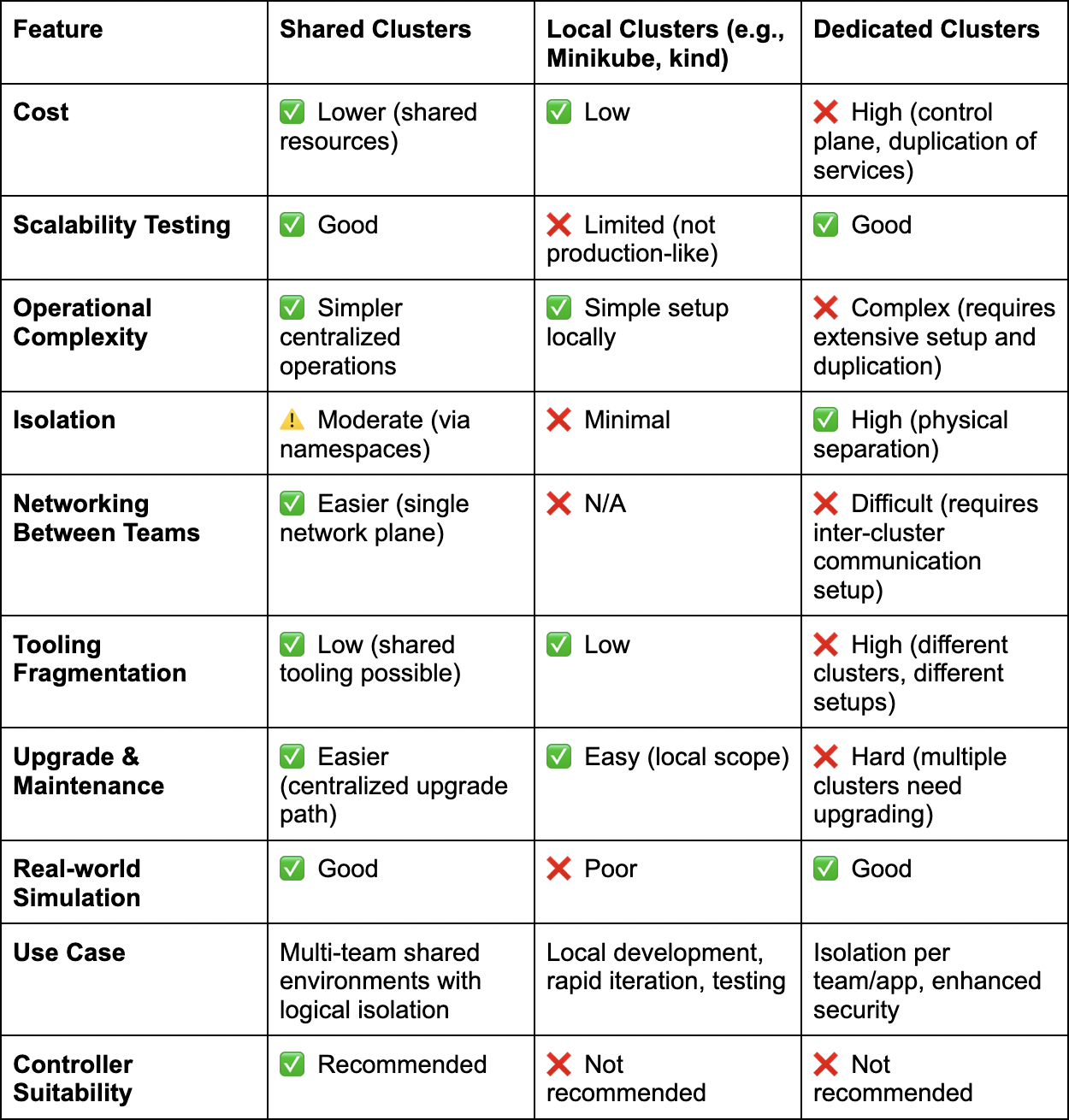
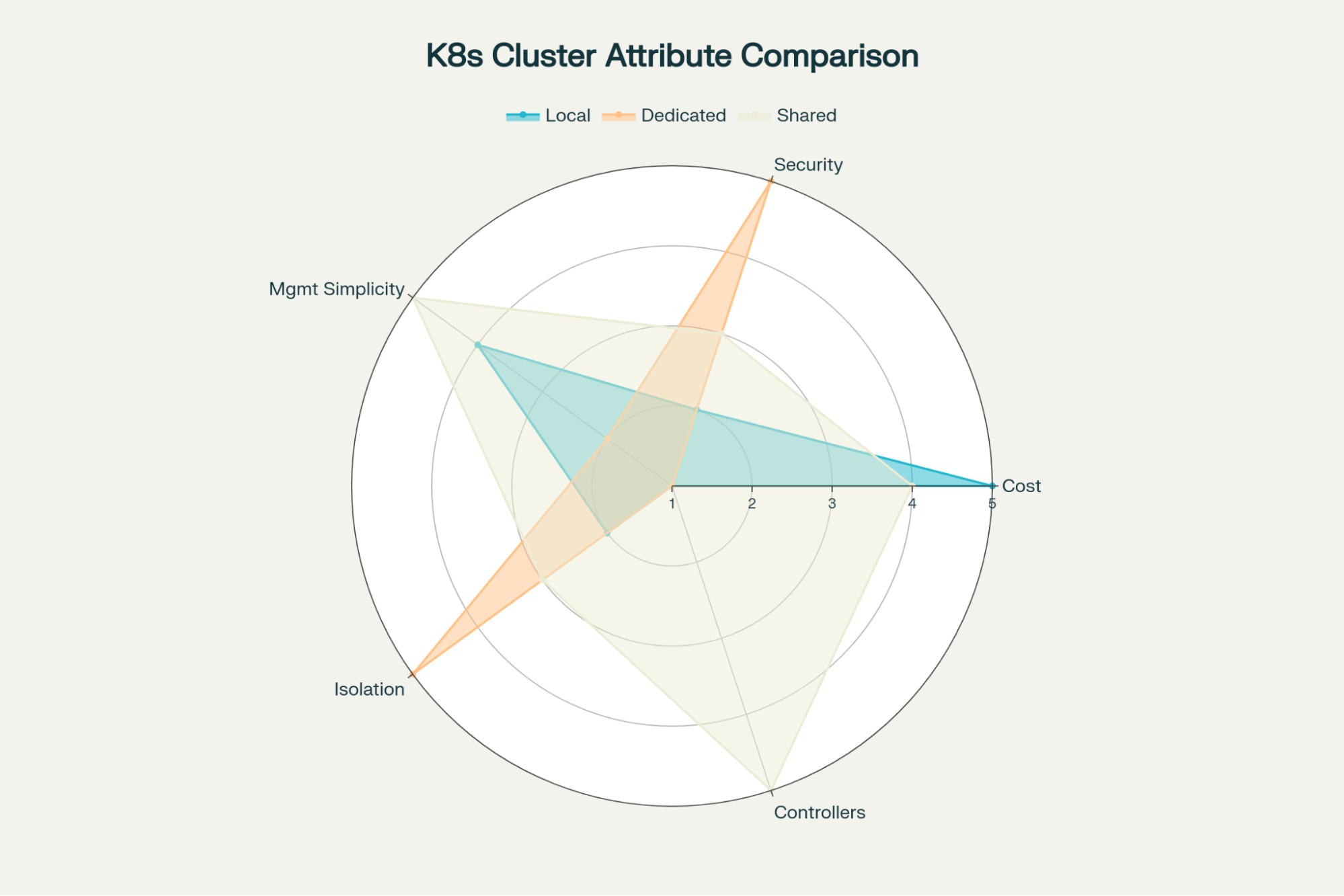
Shared vs Local vs Dedicated Clusters
The structure of Kubernetes environments becomes a strategic decision, but can highly influence productivity and costs. Organizations often choose among these three approaches:
Local Clusters: Kubernetes can be run locally (e.g., using tools like Minikube or kind). This enables rapid iteration and quicker feedback loops but often lacks parity with production environments and can miss real-world scaling, resource exhaustion, and networking issues. It is not recommended for Controllers but can be useful in simple scenarios.
Dedicated Clusters: Each team or application has its own cluster. This model enhances team autonomy, security, and operational flexibility but can be costly due to expenses related to control plane and platform duplication, and it may lead to fragmentation in tooling and management practices. It is not recommended for controllers, as it’s very expensive to dedicate a cluster and it lacks simple connectivity between different clusters without extensive tweaks.
Shared Clusters: A better approach involves multiple teams sharing a single cluster. This allows tenants to share one cluster and test, create, and deploy their applications and controllers from it. There’s no need for configuration across multiple clusters or upgrading various clusters simultaneously. It’s the simplest method, where you can use namespaces to provide some isolation, and IT doesn’t have to worry much about configuration.
The best part? You don’t need to pay for control plane costs for many clusters.
The Shared Cluster Challenge
Shared clusters are a simple approach favored by DevOps teams and work well for a small number of applications. However, as your controllers scale, you need to consider a few key areas:
Developer Experience at Scale
While sharing a cluster between two tenants is relatively straightforward to manage, it becomes less efficient as your tenants and their teams expand. The more engineers working on core components of the internal platform, the more likely they are to interfere with each other.
A good architecture is based on a single source of truth, but with many tenants making changes to a single cluster, the single source can easily diverge from the actual state of your cluster.
Managing Controller Failures
Controllers are essential for platform functionality, but when they crash or act unexpectedly, they can disrupt workloads and cause cascading issues across teams. For example, operators, which are a special kind of controller, can potentially halt the entire system and team on that shared cluster when they fail, creating a single point of failure.
Handling Conflicting CRDs Across Teams
Custom Resource Definitions (CRDs) in Kubernetes are cluster-scoped, meaning only one version can exist per cluster. This creates challenges for platform teams: if one team installs an outdated CRD version for their operator, all other teams must use it as well. Upgrading becomes complicated, especially with evolving APIs like Gateway API, where different operators (e.g., APISIX, Traefik) support various versions. This limitation hinders gradual migrations and rolling upgrades, leading to costly, coordinated changes across all teams.
Additionally, when building your custom CRDs, having a way to test different versions within the same cluster isn’t possible in a shared environment. That slows down platform development because you need dedicated clusters to try out a new CRD, and with larger teams, that can require many clusters, skyrocketing the costs.
Auditing and Governance at Scale
As Kubernetes environments scale and multiple teams manage shared clusters, maintaining effective auditing and governance becomes more difficult. Tracking changes across teams, enforcing compliance policies, and ensuring only authorized users modify critical resources like controller definitions are overlooked in the shared cluster setup.
While role-based access control (RBAC) can restrict access at a high level, it often lacks the granularity to prevent users with modify permissions from altering resources owned by other teams in a shared environment. Your policy engines might have a single configuration, which then requires you to make exceptions for specific items, risking your standard governance.
ETCD Pressure and Cluster State Bloat
Excessive use of CRDs, controllers, and custom resources can strain etcd, leading to high API latencies and decreased cluster performance. While rate limiting can help, it isn't always the best option. A multi-etcd setup can distribute workloads but adds complexity. Although rare, etcd bottlenecks can be significant in multi-tenant or high-scale clusters.
Virtual Cluster: A Required Abstraction
For platform development, challenges can be numerous. Shared clusters address some of these issues, while dedicated clusters, though costly, resolve others. Although shared environments are cost-effective and easier to maintain at smaller scales, they can become bottlenecks instead of enabling productivity without strong isolation.
Resource contention, security concerns, and operational friction often hinder team progress. Virtual clusters, a core ability of vCluster, offer a lightweight, Kubernetes-native way to provide teams with isolated environments and their own control planes within a shared physical cluster.
Each virtual cluster functions like a fully operational Kubernetes cluster, including its own API server, namespace management, CRD definitions, and controller lifecycle, eliminating the disadvantages of shared clusters while maintaining cost efficiency.
The ultimate goal of any platform is to build systems that make developers productive. Challenges from shared environments slow down teams. As shown below, you can have different CRDs and operators for a single team during platform development:
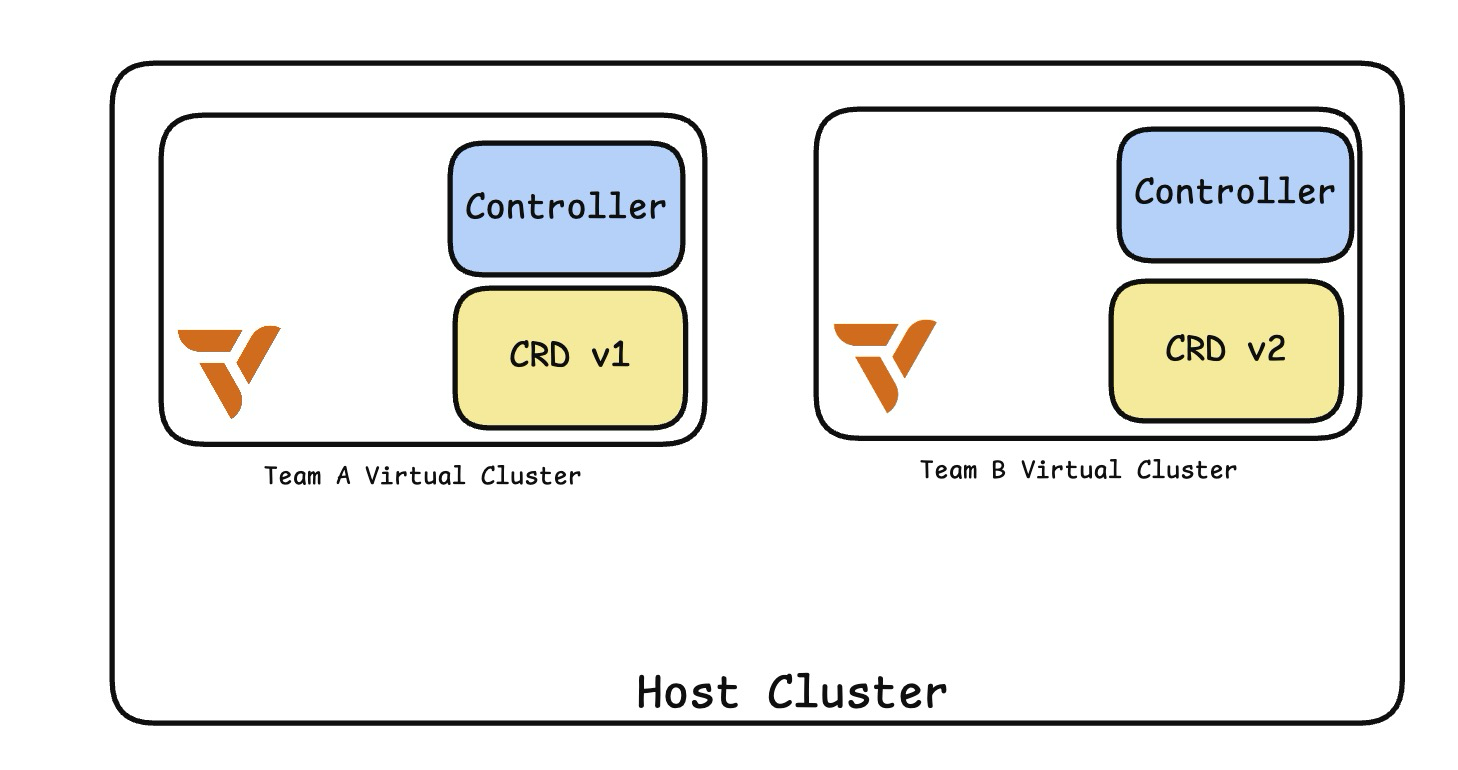
With vCluster, you remove bottlenecks and reduce the coordination required between teams to utilize shared environments.
Final Thoughts
Platform engineering is becoming central to how organizations build internal tooling on Kubernetes. Traditional cluster strategies, shared, local, or dedicated, are starting to show their limits. The platform development lifecycle influences developer productivity, and having a resilient platform that doesn’t slow down is essential.
vCluster covers the entire multi-tenancy spectrum and strikes a new balance between cost, isolation, and developer velocity. They allow teams to build, test, and deploy controllers and CRDs in realistic environments without operational risks or excessive overhead. For organizations scaling Kubernetes as an internal platform, virtual clusters aren’t just a nice-to-have, they’re a foundational abstraction that makes team more efficient while reducing costs.
To learn more: Get started with our docs here, and join our Slack to talk to the team behind vCluster!

.png)
