
.png)
Table of Contents
Whether you are a GPU provider for your internal team or you are doing it for your project, it's important to keep the data with you and have the GPU’s as close as possible for maximum performance and security. This is the trend I have seen while talking with customers. In recent years, with the rise in AI, LLM’s this architecture has become even more prominent and people with their existing bare metal Kubernetes setups have taken UP GPU boxes and figured out how to work them out the best way possible. Let me walk you through some of the problems that the organisations are failing and then a few solutions that might solve your problem.
Managing GPU-based workloads at scale comes with its own set of challenges, especially regarding tenant isolation, resource optimization, and operational complexity. The solutions offered in this post are based on what we at LoftLabs think is best based on our solution vCluster.
The Current State of Bare Metal Kubernetes with GPU
Organizations adopting Kubernetes for GPU workloads often opt for bare metal setups because of performance and cost efficiency. Let’s take an example of an enterprise that currently operates a Kubernetes cluster comprising 50 GPU nodes.
The Kubernetes environment is traditionally managed with namespaces as the primary method of tenant isolation. While namespaces offer basic segmentation, they fall short in providing robust isolation and autonomy, leading to numerous operational challenges.
Challenges of Namespace-Based Multi-tenancy:
Limited Tenant Isolation: Namespaces provide weak isolation, leading to risks associated with "noisy neighbors," where workloads from one tenant can negatively impact others.
Restricted Tenant Autonomy: Tenants often lack the ability to manage their own resources, including Custom Resource Definitions (CRDs)
Complex Compliance Requirements: Weak isolation poses regulatory and compliance challenges, particularly for enterprises with stringent security needs.
Operational Complexity and Cost: The inability to autonomously scale and manage workloads forces enterprises into complex administrative workflows.
With a bare metal Kubernetes cluster and having ordered a set of 50 GPU nodes (which are not cheap in any way) you end up in a situation like below.
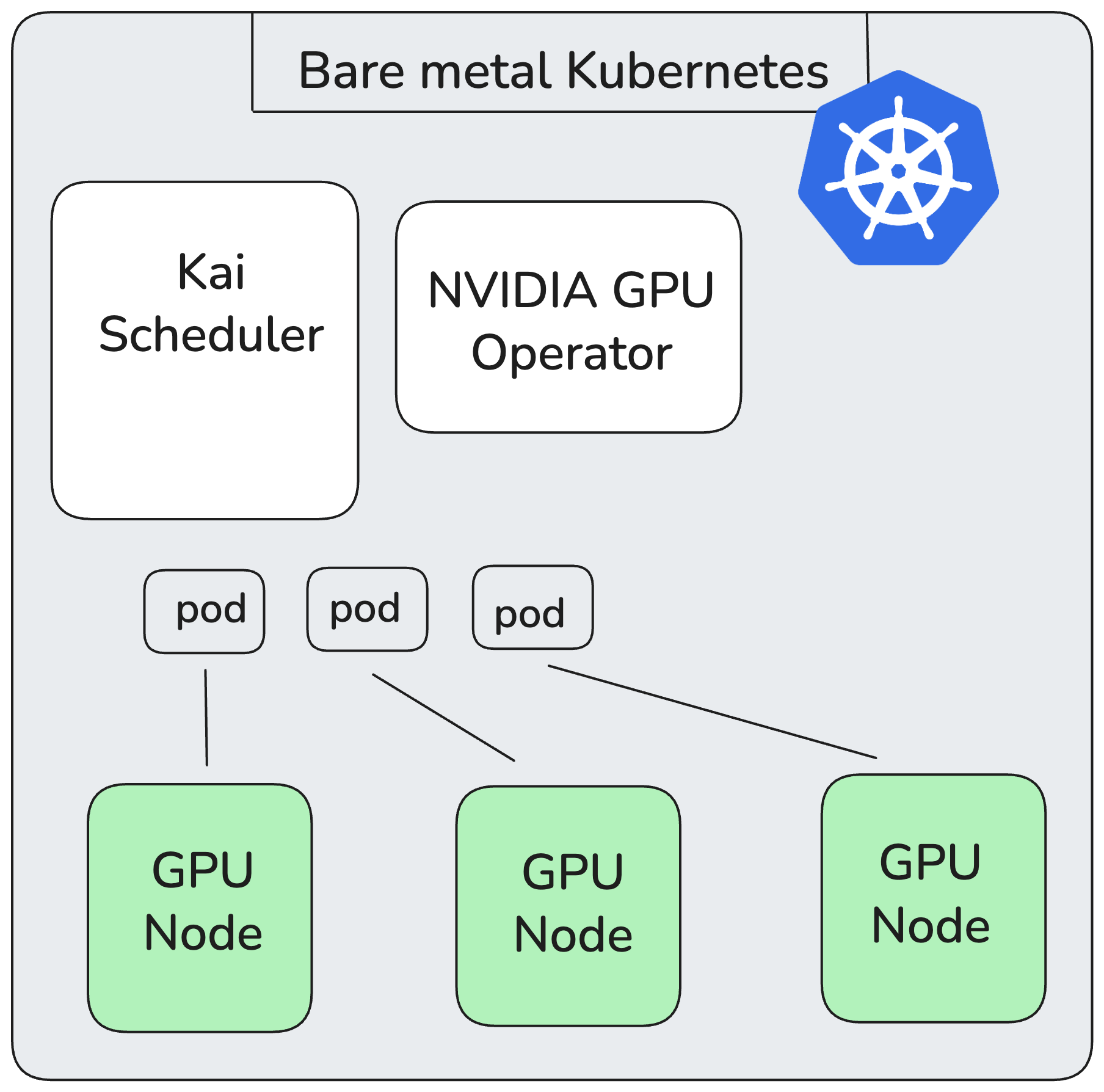
This represents that you have a bare Metal Kubernetes cluster and that cluster is spanned across all the bare metal nodes. Next you attach the GPU nodes to those bare metal instances. But the problem is how do you distribute it among your teams or as a GPU provided (internal or external) how will you manage multi-tenancy? One way can be namespace based where you can have different namespaces for different tenants as below:

Do you see the problem here? The GPU nodes in Tenant B are being effectively utilized, but the GPU nodes in Tenant A are not, this shows even after effective scheduling you might end up underutilizing GPUs from one Kubernetes cluster that the other cluster might have to serve the workloads.
Within each individual cluster, KAI Scheduler remains a powerful asset. It acts as a robust, efficient, and scalable Kubernetes scheduler, specifically designed to optimize GPU resource allocation for AI/ML workloads within that cluster. It enables administrators to dynamically allocate GPUs, manage high-throughput jobs, and ensure fairness among the various consumers operating within that specific cluster. For instance, KAI Scheduler ensures that within Tenant A's cluster, workloads are intelligently placed to maximize GPU utilization, and similarly for Tenant B's cluster. It handles the nuances of GPU topologies and diverse AI job types (from small interactive tasks to large training runs) effectively, but only within its cluster's boundaries.
So, we are on the right track and have the bare metal Kubernetes setup with GPU nodes and a Kai scheduler to effectively schedule the workloads and utilize those GPUs. Let’s try to understand the challenges in this approach and what the possible solutions are.
Despite KAI Scheduler's effectiveness at the cluster level, the architectural choice of separate clusters for each tenant introduce a “too many clusters” problem:
For the two different tenants in the above scenario, there are separate Kubernetes clusters but from the perspective of bare metal, where you have a limited set of compute capacity and each Kubernetes cluster itself requires so many nodes so having a cluster per team is a very expensive operation and also wastes of a lot of resources. Therefore, what should be the solution? Kubernetes Namespaces?
Let's say we go the route of namespaces, how would things look?

Here you can see the node utilization is great and KAI scheduler is doing a good job but then comes another set of problems:
Weak Tenant Isolation: While namespaces give you logical boundaries, they don’t guarantee strong isolation at the control plane or API level. Tenants can accidentally or maliciously interfere with one another. You can add admission controllers and policy engines like Kyverno or OPA-Gatekeeper, but the complexity only increases, and it still doesn’t match the full isolation of a separate Kubernetes control plane.
Tenant autonomy is limited: Teams cannot fully own their environments or extend Kubernetes to suit their needs.
No self-service model: Tenants rely on platform teams for everything from provisioning to scaling. This reduces speed for operations and development and impacts the entire time-to-production.
Non-standard workloads are hard to run: Teams cannot deploy their own operators, schedulers, or custom frameworks like Kai Scheduler unless centrally approved and deployed. They only need to rely on the CRD’s and operators that are central and cannot play around with different operators only for them or different versions of operators than on the host cluster.
In such a scenario, we now face a dilemma:
Cluster-per-tenant: gives isolation and autonomy but wastes resources and increases ops burden.
Namespace-per-tenant: is efficient but insecure and inflexible for autonomous AI teams.
So, what’s the alternative that blends the best of both?
MULTI-TENANCY - Multi tenancy is the key solution, and there are various open source projects that can help you with different levels of multi tenancy, However, in this post I will discuss vCluster.
Lets try to understand three modes of multi tenancy that cover the spectrum from low to higher level of isolation.
Shared Nodes Mode (Default vCluster Mode)

In general, vCluster has a dedicated controlplane which runs as a pod on the host cluster and generates a separate kubeconfig context. As an end user, you never interact with the host cluster, you directly interact with the control plane of the virtual cluster and then the syncer component of the vCluster syncs the resource to and from the virtual cluster as shown in the vCluster architecture above.
In this mode, multiple virtual clusters share the same underlying worker nodes. This is the most resource-efficient approach and allows:
Teams to use custom tooling like Kai Scheduler within their own vCluster
High utilization of expensive GPU nodes
Autonomous control for tenants (CRDs, controllers, admission policies)
However, isolation at the node level is not guaranteed by default. Which is where another project vNode, in combination with vCluster, provides hard isolation where your vClusters run in a virtual node. You can read more about vNode here. In this mode too, the CRI(container runtime interface) and CNI(Container network interface) are shared from the host cluster.
Ideal for: Organizations prioritizing GPU efficiency while still enabling tenant-level autonomy.

This image above is how it looks in the shared multi tenancy mode, and when you combine with bare metal, it looks something like below:

The use of vCluster and vNode together, provides a great solution for secure multi-tenancy clusters, where they can run privileged pods in virtual clusters that run on virtual nodes and even if they breakout, they will get access to the virtual node and not the actual node.
Dedicated Nodes via Node Selectors
In the Dedicated Nodes model, each node in the cluster is labeled and assigned to a specific tenant, enabling clear separation of workloads at the node level. This approach provides the benefits of dedicated hardware for each tenant while maintaining the flexibility to easily rebalance node assignments as demands change. Since tenants still share the underlying cluster infrastructure like CNI and CSI, appropriate isolation policies must be enforced to ensure security and stability.
This gives GPU teams strong boundaries while maintaining cost efficiency.
Ideal for: Teams needing stricter workload placement or tenant-specific hardware policies.

Dedicated Clusters with Private Nodes (Coming Soon)
The Private Nodes model uses a hosted control plane for each tenant, with private, dedicated worker nodes that are not shared with others. This setup effectively creates fully isolated single-tenant Kubernetes clusters, each with its own networking (CNI), storage (CSI), and control components, ensuring maximum security, compliance, and workload separation.
This model is especially useful when regulatory or security requirements demand complete isolation of workloads, data paths, and networking.
vCluster is currently building support for this, making it possible to dynamically provision isolated control planes and private GPU nodes without having to operate a new full cluster for every tenant manually.
Ideal for: Enterprises with strict compliance requirements or highly sensitive AI/ML workloads.

This is the most exciting feature that is coming up for vCluster.
Conclusion
Running a GPU Kubernetes cluster on bare metal is the right choice for getting your AI workloads closer to you and running them securely. There comes a lot of challenges when you want to have different teams having isolated clusters, as bare metal is limited and multiple clusters are expensive. What we have seen is that there are open source solutions for different types of tenancy modes to run AI workloads on Kubernetes with efficient GPU sharing and cluster sharing among different teams, but vCluster stands out as the most flexible solution out there. Solutions like Kamaji, Capsule, RedHat Hypershift exist, but they solve one part of the multi-tenancy puzzle but vCluster covers the entire multi-tenancy spectrum.
Would love to know your AI infrastructure architectures and if we can help in making them better.


